How Qube’s Continuous Monitoring Found Leaking Level Controllers After Well Restart
Summary
A Colorado well pad restarted after a non-routine shut-in. Within hours, Qube’s continuous monitoring flagged methane levels consistent with a large release event (estimated at >100 kg/h, about 125 mscf/d). The operator’s LDAR team located badly leaking level controllers and multiple thief hatches and completed repairs in under 24 hours. The operator then initiated a fleet-wide replacement of aging controllers to prevent recurrence.
Who this helps
HSE leads
Operations supervisors
LDAR coordinators
Production teams
Anyone who needs fast detection, clear localization, and operational follow-through during restarts.
Background: Restarts can be high-risk windows
After planned or emergency shut-ins, systems return to pressure and flow that can overwhelm aging pneumatics and seals. Intermittent, high-rate events often occur in the first hours after restart. A snapshot LDAR survey rarely lands during that window. Continuous monitoring’s always on, real-time detection makes it ideal for emissions detection in this situation.

Field Response: From alarm to repair in under 24 hours
Within hours of restart, Qube’s site sensors observed unusually high methane concentrations and triggered automated alarms. The estimated release rate exceeded 100 kg/h (about 125 mscf/d), which put the event into “act now” territory for both cost and compliance.
Step 1. Alert and Dispatch: LDAR team mobilized immediately with the source area mapped by Qube.
Step 2. Identify: Technicians confirmed several badly leaking level controllers in the separators and found four leaking thief hatches.
Step 3. Repair: Controllers were repaired or isolated, thief hatches reseated or replaced.
Step 4. Verify: Post-repair readings returned to baseline.
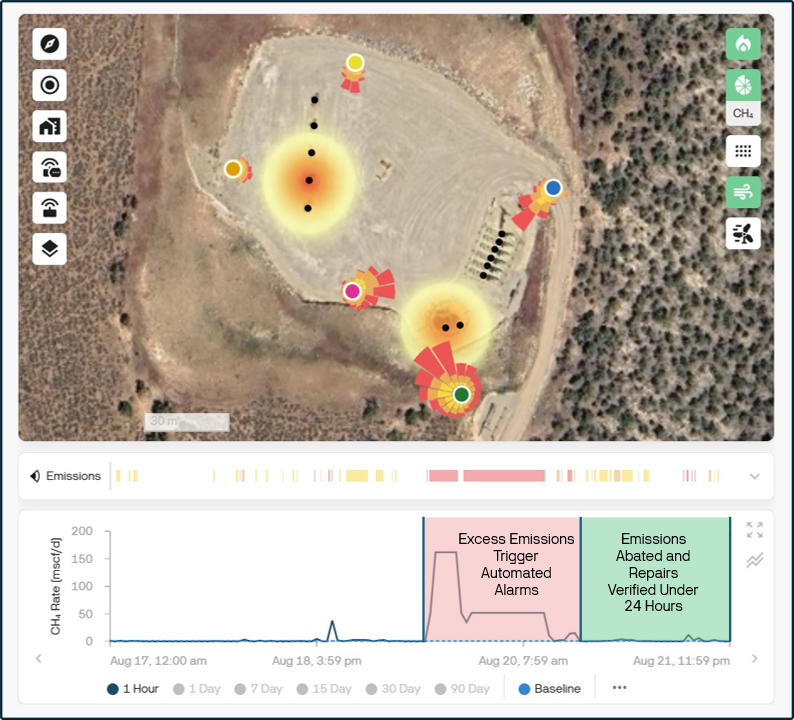
Figure 1 – Elevated methane emissions from leaking level controllers were detected by Qube’s continuous monitoring following a well pad restart. The LDAR Team identified the source and completed repairs in under 24 hours.
Why this matters for operators
Restarts drive intermittent, high-rate events. You need coverage in the exact hours when risk peaks.
Localization saves hours. Going straight to the emissions sources, separators and thief hatches, cuts site time and avoids guesswork.
Data turns fixes into programs. Event data plus repair verification created a defensible ROI for a fleet-wide controller replacement program.
Playbook: Applying this at your sites
Before restart
Confirm controller set points and function checks for separators.
Inspect thief hatch seals and latches.
Ensure monitoring is online and alarm set points and notifications are current.
During restart
Watch for sharp concentration increases and wind-aligned plumes.
Use auto-localization to prioritize equipment rows.
After repair
Verify with live readings, log the event, and tag assets for reliability review.
Roll up learnings into a replacement or retrofit plan.
FAQs
-
The event occurred within hours of restart. Periodic surveys rarely align with that window.
-
Qube’s continuous monitoring solution has been field-tested in extreme environments across the world and provides a reliable measurement to trigger LDAR response and prioritize equipment. The post-repair return to baseline confirms a successful repair outcome for operators and auditors.
-
The “always-on” nature of continuous monitoring means that there is a much higher likelihood of capturing emissions events across changing wind conditions that single pass methods can miss.
Explore our other resources and case studies or reach out directly.